事前知識をつめこむと、Bayesian深層学習はもっと賢くなるよ!という論文を読む
おもしろい論文紹介に出会ったので、自分でも少しだけ理解をがんばってみました。
Bayesian Neural Net(BNN)では事前分布がうまくチューニングできていないと、モデルがしょぼいという内容です。だから、事前分布のチューニングをしよう!という話を提案しています。
BNNの事前分布をチューニングしよう、なんて考えたことすらなかったので、個人的に新鮮な印象でした。
タイトルはInformative Bayesian Neural Network Priors for Weak Signals。Weak Signalsってなんでしょうか?気になりますね。
Bayesian Neural Net(BNN)を遺伝データに合わせてパラメタチューニングする、という内容です。

以下、スクショと引用は、すべて上記のarxivのv2からです。
目次
問題意識
遺伝データではデータ構造がすっかすか
そもそも、問題意識がどこにあるんだ?という話です。
論文によると、遺伝データでは、featureのほとんどが役に立たないという状況が発生するそうです。
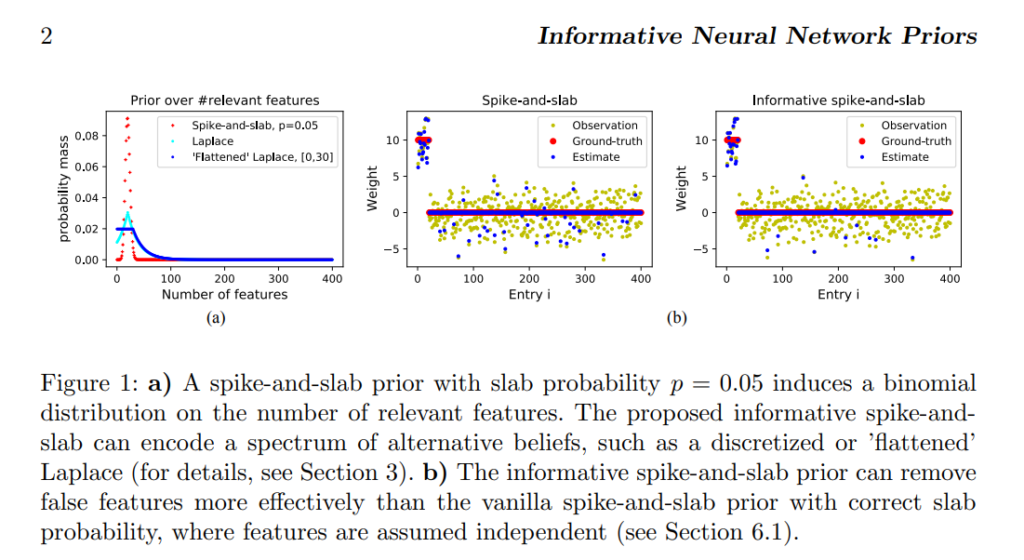
(b)の2つの図は遺伝データの状況を表しています。意味をもったfeatureは赤点だけで、ほかのすべての点は意味をもたないデータポイントとされてます。
論文はこの状況をspacityと表現しています。
BNNは事前分布に依存する
そもそもニューラルネットの挙動は何によって決まるのでしょうか?重みですね。
では、BNNの初期重みはどこから来るのでしょうか?事前分布ですね。
つまり、良いBNNモデルを作るためにはデータに適切な事前分布を選ぶ必要があるという理屈ができます。
Sparsityを事前分布に埋め込めないか?
遺伝データに良いBNNにするためには、sparsityをうまく表現できる事前分布でなければいけません。
この課題を定式化すると「BNNモデルがsparsityデータへの当てはまる指標(目的関数)を定義し、指標を最小化すればいい(最適化問題)最適化結果、sparsityデータに適した事前分布ができあがる」と表現できます。
ここで、Spacityデータ -> BNN -> 出力 をうまく表現できる指標を持ってきましょう。ということで論文はPVEを持ってきます。式(3)です。[1] PVE??なんやそれ?って思いました。

ここで関数はBNNだとします。式3を見ればわかるとおり、分子で関数を呼び出ししています。PVEを直感的に表すと、「データの真分布と予測の誤差をスケール化した値」と言えます。直感的に書きすぎると、最小二乗誤差と違いがないように聞こえますね(笑)
そして、良いBNNモデルを得ることを論文では、次のように言っています。

上のテキストが言ってることをイラストで描くと、こんな様子になります。イラストでVPE とはPVEの誤植です [2] 聞いたことない言葉を無理して使うから。。。
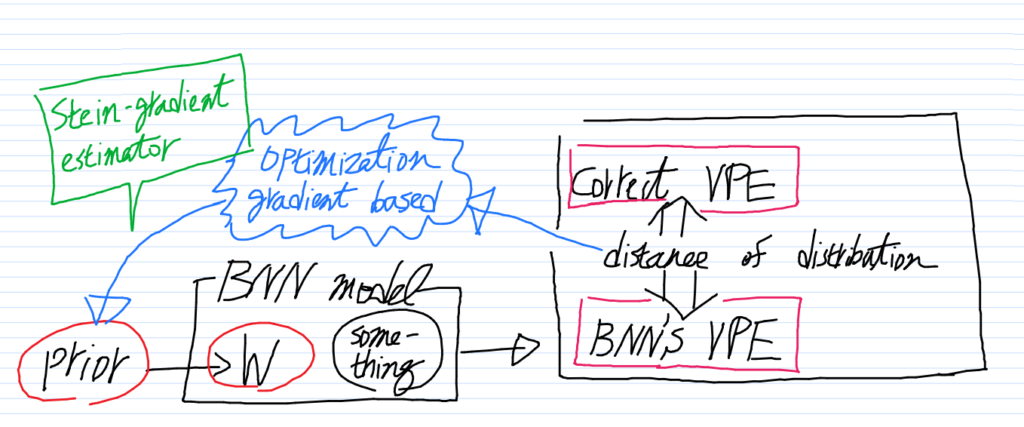
要するに、この論文が目指しているのは、上のフレームワークです。
PVEの出力は分布です。Fig 2の(a)がPVEのわかりやすいイメージです。
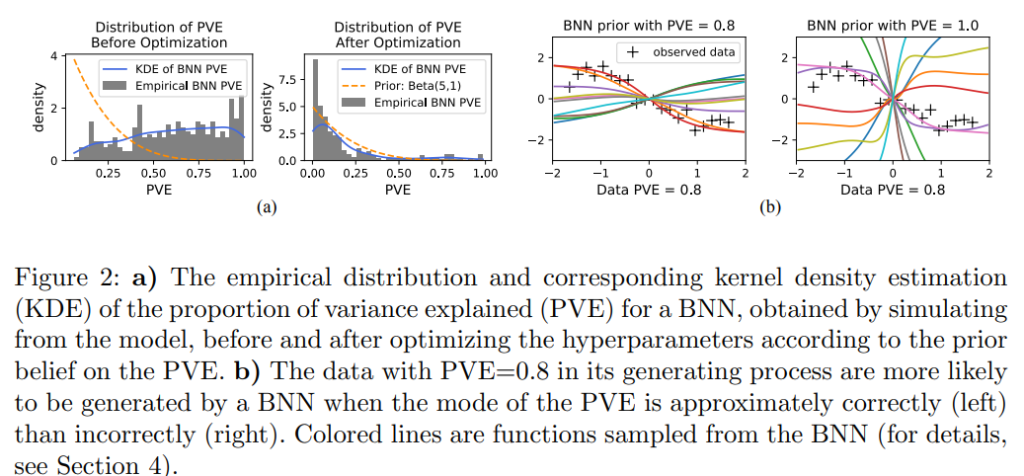
最適化を式で定義しよう
厳密なことはすっとばしますが、かいつまんで問題の定式化を追ってみます。
まず、全体像が見えた方がわかりやすいと思うので、先に全体像だけを書いてしまいます。[3] … Continue reading
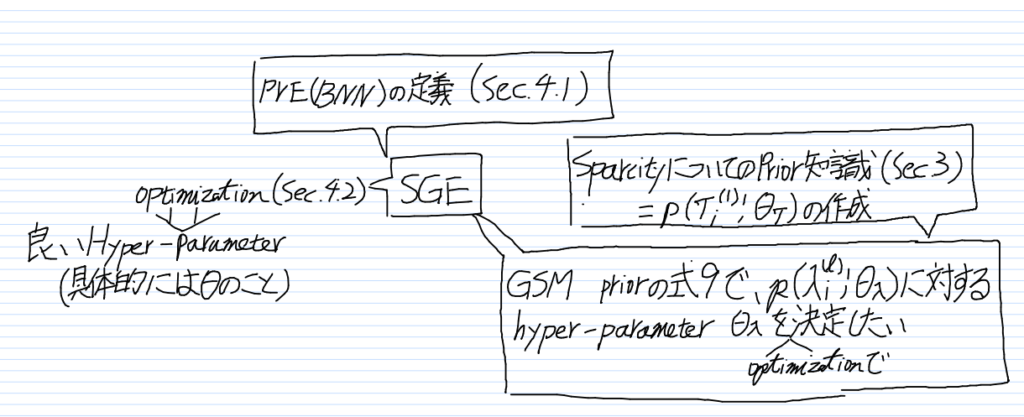
事前分布をモデルに埋め込む(Sec. 2.2)
って、どうしたらいいんでしょ?[4] Bertなんかだと、知識ベクトルをもってきて、ひょいひょういと埋め込みしたら、なんかいい感じになってますよね
BNNにおける知識とは「分布」です。
ここで振り返りすると、BNNの重みはどの式で決まるんでしたっけ?Automatic Relevance Determination(ARD)を使うことが多いです。[5] と、論文に書いてある。ぼくは知らん
で、いま、この論文は分布である知識を、重みに導入したい・・・と。それは混合分布問題(GSM: Gaussian scale mixture)ということになります。ということは、これはGSM ARDと定義できます。GSM ARDは式5で表現できます。
で、話は変わるんですが、データのSparsity性とGSM ARDのパラメタの依存関係を考えてみましょう。論文はグラフィカルモデルで表現してます。
ぼくが理解のために色をつけておきました。厳密性をふっ飛ばして依存関係を書いてみます。
λはSparsityに依存します。そして、τはλに依存します。

つまり、ここから言えることは、まずλのパラメタを最適化し、つぎにτのパラメタを最適化すればいい、ということがわかります。
目的関数の距離を測るためにStein Gradient Estimator
いきなり話は飛びます。最適化をしたいわけですから、目的関数値と真の値の距離を小さくしたいわけです。
で、ぼくたちはPVEを指標に使うことにしました。さらに、PVEは分布であることを書きました。
分布なんですよ。じゃあ、分布の距離計算ってどうするんでしたっけ?KL Divergenceですね。
でも、いまのアプローチではKL Divergenceを使えないのです(泣)
その理由を論文の式21のあたりに書いてあります。

ここでq_θ_λ (p(w)) は「BNNの出力で計算したPVE」と思っておけばいいです。q_θ_λ (p(w))の計算過程はBNNなわけですから、解析的に追跡することができません[6] not analytically tractableとはこういう意味だと思う。たぶん!
そこで、論文はKL Divergenceの近似を考えます。すると、線形な計算に変形できるわけですね。
線形な式を見ると、logを取ったpとqがありますよね。logの計算すんの?って話ですよ。いやいや、そんなご冗談を。Stein Gradient Estimatorを使うに決まってるじゃないですか[7] いままで知らなかったくせに、知ったかぶり
Stein Gradient Estimator
ここでStein Gradient Estimatorが登場します。[8] シュタインズゲートみたいな名前でかっこいですね棒。Steinとはドイツ語で石です。でも、 人名でよく使われます

Stein Gradient Estimatorとは、q(z)からのサンプルだけで、log q(z)の微分を近似します。と書いてありますね。マジで?やばくね? [9] ぼくはぜんぜん知りませんでした。不勉強です
Stein Gradient Estimatorの式を追っていくと、G と Kという表記が出てきます。あれ、、、これってもしかして・・・そう、カーネル空間です。
つまり、Stein Gradient Estimatorはカーネル空間の近似、と簡単に言うことができます。
KL Divergenceのカーネル空間バージョン
元のKL Divergenceを、Stein Gradient Estimatorによって、カーネル空間に飛ばしているわけですから、こいつはKL Divergenceのカーネル版と言ってもよさそうです [10] 本当はちょっと心配。合っているのか?
つまり、カーネル空間での分布が同じであれば、元の空間でも分布の同一性が言える、とそういう理屈になります。
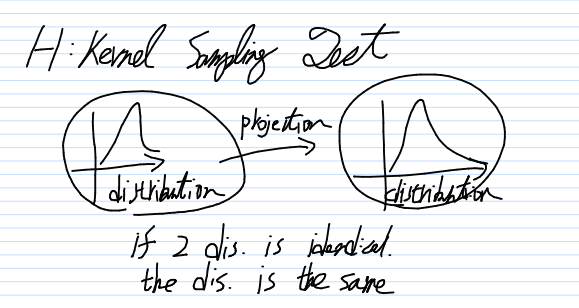
おさらいしてみる
最初にはった関係図をもう一度だけ持ち出します。
理屈としてはこうなります。
解きたい問題は最適化 (Sec. 4.2)。最適化の結果は良いθを得られる。
最適化のためにStein Gradient Estimatorで変形したKL Divergenceを目的関数にする。
目的関数を書くために2つのことをする。
1つは、Sparsityとτとλの依存関係の定式化(Sec. 3)
2つは、PVE(BNN) を定義しないといけない(Sec. 4.1)
という提案手法でした。実験を読むのはやめました。途中で疲れてしまった。
ぼくにとってはおもしろい内容でした。
BNNのチューニングを真面目に考えたことなかったし、事前分布をいじろうなんて考えもしなかった。
Stein Gradient Estimator(俗称: シュタエス)っていうかっこいい(名前的に、アプローチ的に)道具を知ることできたので、満足。
満足感が高かったので、記事に書き残しておくことにしました。
お気持ち的な
この論文を理解するのはけっこーしんどかったです。さらりと論文の全体像をつかむだけで1時間くらいかかりました。
記事中の落書きは、ぼくが理解するために図で表現した者共です。
はじめて触る分野の研究はこれくらいにざっくりと理解する読み方アプローチが良さそうだな、とひとつ経験を得ました。
ところで、遺伝データのようなSpatsiryを持ったデータには他にどんな例があるのだろう?気になるところです。
Footnotes
| ↑1 | PVE??なんやそれ?って思いました。 |
|---|---|
| ↑2 | 聞いたことない言葉を無理して使うから。。。 |
| ↑3 | ちゅーか、この分野に素人のぼくには、まず全体像を説明してくれ!!個々を丁寧に説明されてもわからへんのや!!と読みながら思った。素人にはそれくらいでいいのです。 |
| ↑4 | Bertなんかだと、知識ベクトルをもってきて、ひょいひょういと埋め込みしたら、なんかいい感じになってますよね |
| ↑5 | と、論文に書いてある。ぼくは知らん |
| ↑6 | not analytically tractableとはこういう意味だと思う。たぶん! |
| ↑7 | いままで知らなかったくせに、知ったかぶり |
| ↑8 | シュタインズゲートみたいな名前でかっこいですね棒。Steinとはドイツ語で石です。でも、 人名でよく使われます |
| ↑9 | ぼくはぜんぜん知りませんでした。不勉強です |
| ↑10 | 本当はちょっと心配。合っているのか? |